LLM 配置指南
LLM(大语言模型)是 VideoCaptioner 的核心功能之一,用于字幕断句、优化和翻译。本指南将帮助你配置 LLM API。
为什么需要配置 LLM?
- 字幕断句:使用 LLM 进行语义分析,生成自然流畅的字幕分段
- 字幕优化:自动修正错别字、统一专业术语、优化格式
- 字幕翻译:结合上下文的高质量翻译
提示
软件内置了基础 LLM 模型可供测试使用,但配置自己的 API 可以获得:
- ✅ 更稳定的服务
- ✅ 更高的并发能力
- ✅ 更好的处理质量
支持的 LLM 服务商
VideoCaptioner 支持多种 LLM 服务商,你可以根据自己的需求选择:
| 服务商 | 特点 | 推荐场景 |
|---|---|---|
| OpenAI | 质量最好,API 稳定 | 追求极致质量 |
| DeepSeek | 性价比高,中文优秀 | 中文内容处理 |
| SiliconCloud | 国内可用,模型丰富 | 国内用户 |
| Gemini | Google 出品,免费额度大 | 预算有限 |
| Ollama | 完全本地运行,免费 | 隐私敏感场景 |
| LM Studio | 本地运行,图形化界面 | 本地部署 |
| ChatGLM | 国产模型 | 国内用户 |
配置方法
方式一:使用 SiliconCloud(推荐国内用户)
SiliconCloud 集成了国内多家大模型厂商,使用方便。
步骤:
注册账号
访问 SiliconCloud 注册账号(通过链接注册可获得额外额度)
获取 API Key
登录后,在 设置页面 获取 API Key

在 VideoCaptioner 中配置
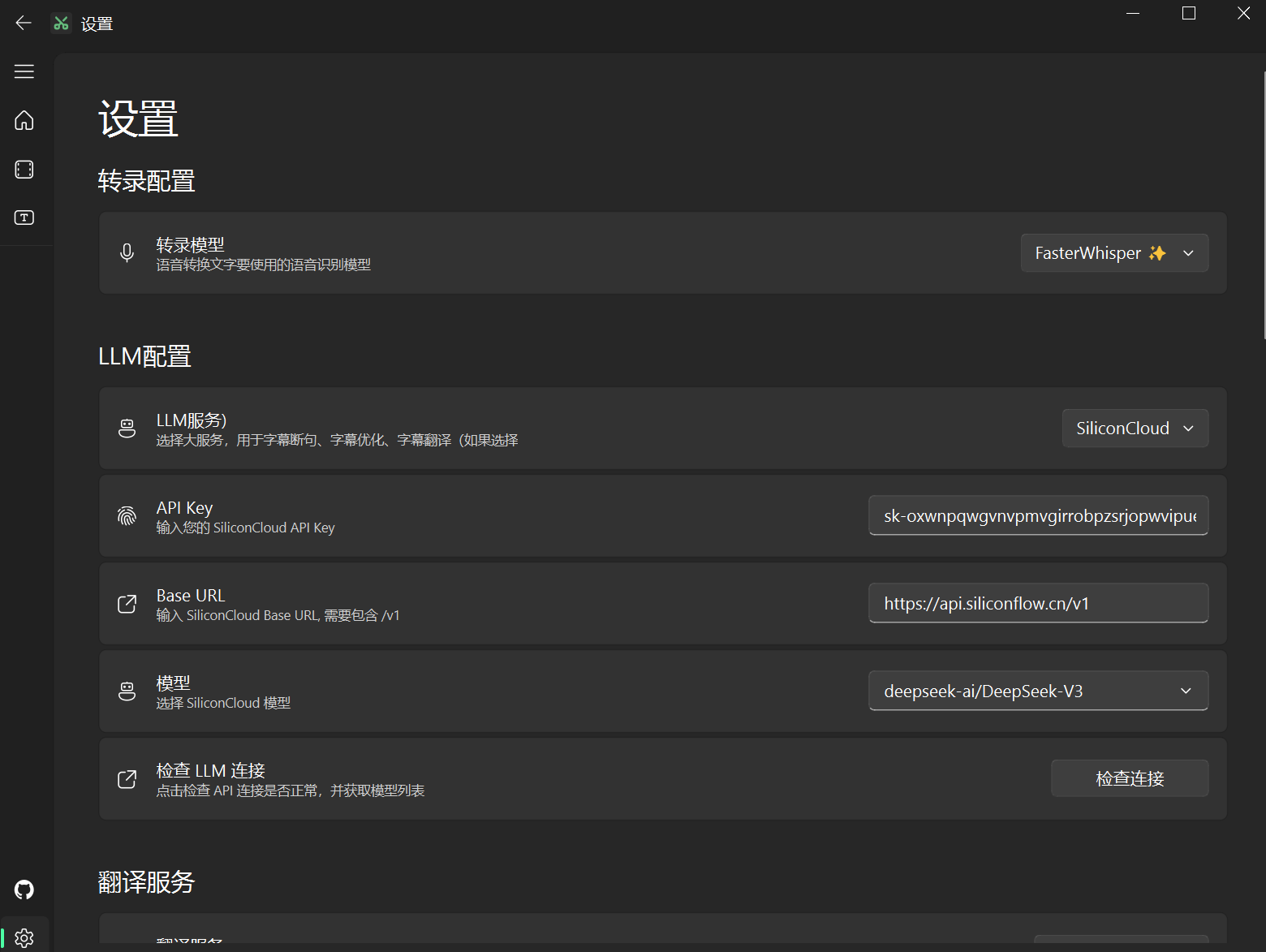
打开 VideoCaptioner,进入 设置 → LLM 配置:
- LLM 服务: 选择
SiliconCloud - API Base URL:
https://api.siliconflow.cn/v1 - API Key: 粘贴你的 API Key
- 点击 "检查连接" 测试配置
- 模型选择: 推荐
Qwen/Qwen2.5-72B-Instruct或deepseek-ai/DeepSeek-V3
- LLM 服务: 选择
配置线程数
SiliconCloud 并发能力有限,建议设置:
- 线程数: 5 或更少
注意
自 2025 年 2 月 6 日起,未实名用户每日最多请求 DeepSeek-V3 模型 100 次。如不想实名,可考虑使用其他中转站或模型。
方式二:使用 OpenAI
如果你有 OpenAI 账号和 API Key:
访问 OpenAI Platform 获取 API Key
在 VideoCaptioner 中配置:
- LLM 服务: 选择
OpenAI - API Base URL:
https://api.openai.com/v1 - API Key: 你的 OpenAI API Key
- 模型选择:
- 经济实惠:
gpt-4o-mini - 高质量:
gpt-4o或gpt-4-turbo
- 经济实惠:
- LLM 服务: 选择
线程数配置:
- OpenAI API 支持较高并发,可设置 10-20 个线程
方式三:使用 DeepSeek
DeepSeek 是一个性价比极高的国产 LLM。
访问 DeepSeek 平台 注册并获取 API Key
在 VideoCaptioner 中配置:
- LLM 服务: 选择
DeepSeek - API Base URL:
https://api.deepseek.com/v1 - API Key: 你的 DeepSeek API Key
- 模型选择:
deepseek-chat或deepseek-coder
- LLM 服务: 选择
线程数配置:
- 建议 5-10 个线程
方式四:使用本项目中转站(推荐)⭐
本项目提供了高性价比的 LLM API 中转站,支持多种优质模型和高并发。
特点:
- ✅ 支持 OpenAI、Claude、Gemini 等优质模型
- ✅ 超高并发能力,处理速度极快
- ✅ 稳定可靠,专为本项目优化
- ✅ 国内可直接访问
配置步骤:
注册账号
访问 https://api.videocaptioner.cn/register 注册(通过链接注册赠送 $0.4 测试余额)
获取 API Key
登录后访问 Token 页面 获取 API Key
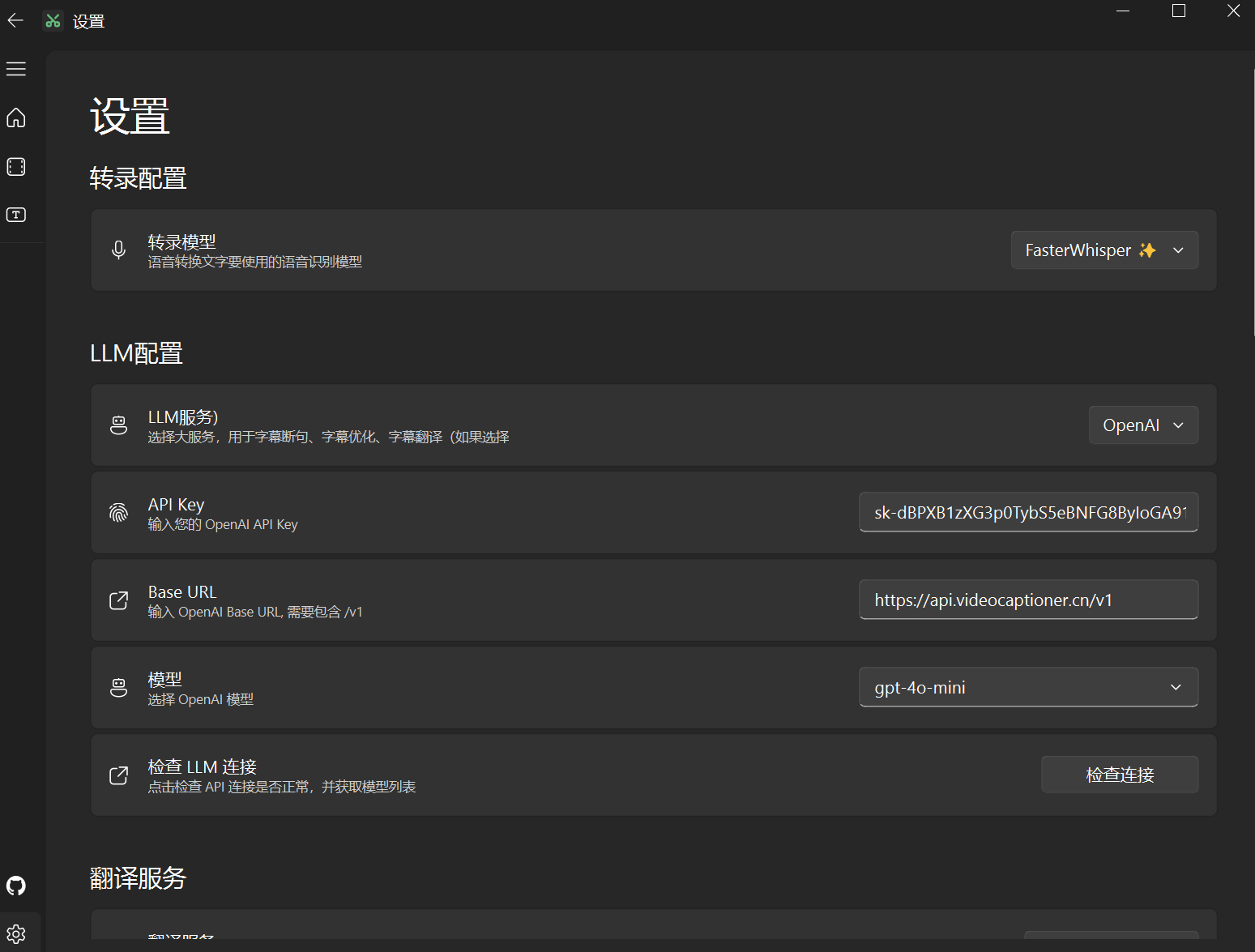
在 VideoCaptioner 中配置
- LLM 服务: 选择
OpenAI(兼容模式) - API Base URL:
https://api.videocaptioner.cn/v1 - API Key: 你获取的 API Key
- 点击 "检查连接" 测试
- LLM 服务: 选择
模型选择建议
根据预算和质量需求选择:
质量层级 推荐模型 耗费比例 适用场景 高质量 gemini-2.0-flash-expclaude-sonnet-4.5-202509293 重要内容、专业翻译 较高质量 gpt-4o-2024-08-07claude-haiku-4-5-202510011.2 日常使用、高质量需求 中质量 gpt-4o-minigemini-2.0-flash-exp0.3 快速处理、预算有限 线程数配置
中转站支持超高并发,可以直接拉满:
- 线程数: 20-50(根据你的网络和机器性能)
推荐配置
- 日常使用:
gpt-4o-mini+ 30 线程 - 追求质量:
claude-sonnet-4.5+ 20 线程 - 预算有限:
gemini-2.0-flash-exp+ 50 线程
方式五:本地部署 Ollama
如果你希望完全本地运行,保护隐私:
安装 Ollama
访问 Ollama 官网 下载并安装
下载模型
bash# 下载推荐模型 ollama pull llama3.1:8b # 或下载更大的模型 ollama pull qwen2.5:14b启动 Ollama 服务
bashollama serve在 VideoCaptioner 中配置
- LLM 服务: 选择
Ollama - API Base URL:
http://localhost:11434/v1 - API Key: 留空或填写任意值
- 模型选择: 你下载的模型名称(如
llama3.1:8b)
- LLM 服务: 选择
线程数配置
根据你的硬件配置:
- CPU: 2-4 个线程
- GPU: 4-8 个线程
注意
本地模型的质量通常不如云端 API,建议使用 14B 以上参数的模型。
高级配置
自定义提示词
在字幕优化和翻译时,你可以添加自定义提示词来改善输出质量:
示例:
请注意以下专业术语:
- 机器学习 -> Machine Learning
- 深度学习 -> Deep Learning
- 神经网络 -> Neural Network
请保持技术术语的准确性,不要过度意译。在 字幕优化与翻译 页面的 "文稿提示" 输入框中填写。
并发线程数调优
线程数影响处理速度和成本:
| API 类型 | 推荐线程数 | 说明 |
|---|---|---|
| OpenAI | 10-20 | 支持高并发 |
| 中转站 | 20-50 | 专为高并发优化 |
| DeepSeek | 5-10 | 有一定并发限制 |
| SiliconCloud | 3-5 | 并发能力较弱 |
| Ollama 本地 | 2-8 | 取决于硬件性能 |
提示
如果遇到 请求超时 或 429 错误,说明并发过高,需要降低线程数。
温度参数(Temperature)
温度参数控制模型输出的随机性:
- 0.1-0.3:输出更稳定、保守(推荐用于字幕优化)
- 0.5-0.7:输出更自然、灵活(推荐用于翻译)
- 0.8-1.0:输出更有创意(不推荐)
默认值 0.3 适用于大多数场景。
费用估算
使用 LLM API 会产生一定费用,以下是参考估算:
示例:处理 14 分钟视频
- 转录字数:约 2000 字
- 使用模型:
gpt-4o-mini - 处理流程:断句 + 优化 + 翻译
- 总费用:< ¥0.01
说明
- LLM 仅处理文本内容,不包含时间轴信息,Token 消耗很少
- 翻译采用 "翻译-反思-翻译" 方法,费用会相应增加
- 使用批量处理时,费用基本按视频数量线性增长
常见问题
连接测试失败
解决方案
检查 API Key 格式
- OpenAI: 以
sk-开头 - 其他服务商可能有不同格式
- OpenAI: 以
检查 Base URL
- 必须包含
/v1后缀 - 不要有多余的斜杠
- 必须包含
检查网络连接
- 某些服务商需要科学上网
- 检查防火墙设置
查看详细错误
- 在 设置 → 日志 中查看详细错误信息 :::
请求频繁失败
解决方案
降低线程数
- 从 20 降低到 10 或 5
检查 API 额度
- 登录服务商平台查看余额
更换服务商
- 尝试使用本项目中转站
检查模型可用性
- 某些模型可能有地区限制 :::
输出质量不佳
解决方案
更换更好的模型
gpt-4o-mini→gpt-4ogemini-1.5-flash→gemini-2.0-flash-exp
调整温度参数
- 降低温度(如 0.3 → 0.1)获得更稳定输出
添加文稿提示
- 在文稿提示中添加术语表和修正要求
使用反思翻译
- 在翻译设置中启用 "反思翻译" :::
推荐配置方案
新手推荐
服务商: 本项目中转站
模型: gpt-4o-mini
线程数: 20
温度: 0.3追求质量
服务商: 本项目中转站
模型: claude-sonnet-4.5
线程数: 15
温度: 0.3
反思翻译: 开启预算有限
服务商: SiliconCloud
模型: Qwen/Qwen2.5-72B-Instruct
线程数: 5
温度: 0.3隐私优先
服务商: Ollama(本地)
模型: qwen2.5:14b
线程数: 4
温度: 0.5如果还有其他问题,欢迎在 GitHub Issues 提问。